Hidden Value in Estimation
Picture a planning meeting. The attendees this week are the product manager, a product designer and three software developers. Previously the team chose to adopt the Fibonacci sequence as their points scale.
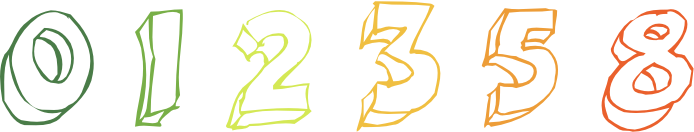
After reviewing a story it’s up to the software developers to provide estimates for this particular backlog. There are three scenarios which might occur, expressed in estimates:

2, 2, 3: The estimates are close enough to consensus. The story can be worked on.

Pass, 8, Pass: This story can’t be estimated by everyone. The story will probably need to be revised or broken down.

8, 2, 2: There’s a notable difference in estimates.
Counterintuitively the last scenario with a spread of estimates can be a highly valuable eventuality (in limited doses).
If there’s enough time for a brief explanation of why everyone voted as they did, there’s an opportunity for team members to share information their colleagues may not be aware of or didn’t recall. You might hear how a similar feature has been implemented before, so a lower estimate is appropriate. Alternatively a high estimate may consider a previous decision which affects the new feature.
After everyone has a moment to reflect another vote can be held. If there’s still a spread of estimates after the subsequent vote, ignore the outliers, figure out a midpoint and move on. There’s no value in total agreement — especially if points are abstract. In this scenario the value realised in the discussion following the first vote. The team’s shared understanding of the problem they’re collectively trying to solve has grown.
An Off The Rack Scale
Ideally the points your team use to estimate are abstract; they don’t equate to a time duration and aren’t used to forecast delivery of features for external deadlines. Estimation at its best supports intra-team activities, like relative prioritisation and building that shared understanding. Often teams only reach this state when they’ve earned trust within an organisation by delivering value.
If your team are fortunate enough to consider story points don’t equate to time, do they still need to be numbers? How about switching to t-shirt sizes? Small, medium, large. Sounds straightforward - especially if the range of sizes doesn’t expand over time.
One small tweak I’d suggest is to use:
- Small
- Large
- Huge
Why no medium size? Because it leaves the door open to bikeshedding. Is this a small or medium? Oh maybe it’s a medium or a large? It really doesn’t matter.
With this scale a team could start with following shared definitions:
| Estimate | Meaning |
|---|---|
| Small | It’s smaller than large. |
| Large | It’s larger than small. Interesting… |
| Huge | This is too big for the team to work on / has too many unknowns. |
If a story is estimated as huge then it needs to be sliced up, clarified or researched with a spike.
Small vs large? It might be reasonable to expect that on a Friday at 10am, a small story sitting ahead of large story in the backlog will probably allow an improvement to ship sooner than if their positions were flipped, but nothing’s a given — they’re all estimates.